| Pytorch深度学习:使用SRGAN进行图像降噪 | 您所在的位置:网站首页 › pytorch tensor transpose › Pytorch深度学习:使用SRGAN进行图像降噪 |
Pytorch深度学习:使用SRGAN进行图像降噪
|
前言 本文是文章:Pytorch深度学习:使用SRGAN进行图像降噪(后称原文)的代码详解版本,本文解释的是GitHub仓库里的Jupyter Notebook文件“SRGAN_DN.ipynb”内的代码,其他代码也是由此文件内的代码拆分封装而来的。 1. 导入库import torch import torchvision import torch.nn as nn import torchvision.transforms as transforms from torch.utils.data import Dataset, DataLoader, random_split, TensorDataset import os import time import cv2 import random import skimage from skimage.util import random_noise import numpy as np from PIL import Image from PIL import ImageFile from earlystopping import EarlyStopping from loss import * #自定义的loss函数,后面会解释 import matplotlib.pyplot as plt import hiddenlayer as hl2. 设定初始参数n_blocks = 5 #生成器中的残差块数量 n_epochs = 100 #训练迭代次数 batch_size = 64 #批量大小 train_path = './data/COCO2014/train2014/' #训练数据路径 val_path = './data/COCO2014/val2014/' #验证数据路径 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") #选择在GPU还是CPU上训练 ImageFile.LOAD_TRUNCATED_IMAGES = True #COCO2014的图片里有部分是被截断的图片,默认加载会报错,这行代码意思是仍加载被截断的图片 randomcrop = transforms.RandomCrop(96) #原始图片的大小不一,需要截成同样大小,这里用的是随机裁剪,也可以用其他裁剪方式这部分没什么好说的,这里残差块数量n_blocks只设置了5个,实际上可以多叠几个,我训练下来5个和16个性能差距不大,因此就只用了5个。 3. 数据准备首先定义一下添加高斯噪声函数: def addGaussNoise(data, sigma): sigma2 = sigma**2 / (255 ** 2) noise = random_noise(data, mode='gaussian', var=sigma2, clip=True) return noise接下来自定义Dataset类: class MyDataset(Dataset): def __init__(self, path, transform, sigma=30, ex=1): self.transform = transform self.sigma = sigma for _, _, files in os.walk(path): self.imgs = [path + file for file in files if Image.open(path + file).size >= (96,96)] * ex #上面的意思是仅读取大小大于或等于96*96的图片,ex是数据增广系数,即把同一张图片复制多份以达到扩充数据量的目的 #由于COCO2014数据集训练图片有八万多张,数据量足够大不需要增广,因此ex设置为1 np.random.shuffle(self.imgs) #随机打乱顺序 def __getitem__(self, index): tempImg = self.imgs[index] tempImg = Image.open(tempImg).convert('RGB') #数据集中有部分图片为灰度图,将所有图片转换为RGB格式 Img = np.array(self.transform(tempImg))/255 #像素归一化至[0,1] nImg = addGaussNoise(Img, self.sigma) #添加高斯噪声 Img = torch.tensor(Img.transpose(2,0,1)) #由于Image.open加载的图片是H*W*C的格式,因此转换成C*H*W的格式 nImg = torch.tensor(nImg.transpose(2,0,1)) return Img, nImg def __len__(self): return len(self.imgs)定义一个函数,通过上述MyDataset准备数据,并使用DataLoader加载: def get_data(batch_size, train_path, val_path, transform, sigma, ex=1): train_dataset = MyDataset(train_path, transform, sigma, ex) val_dataset = MyDataset(val_path, transform, sigma, ex) train_iter = DataLoader(train_dataset, batch_size, drop_last=True, num_workers=6) val_iter = DataLoader(val_dataset, batch_size, drop_last=True, num_workers=6) return train_iter, val_iter通过上述get_data函数获得数据集: train_iter, val_iter = get_data(batch_size, train_path, val_path, randomcrop, 30, ex=1)需要说明的是,添加的高斯噪声的均值为0,而方差 \sigma^2_t 是由get_data函数中输入的sigma(\sigma) 通过公式 \sigma^2_t = \frac{\sigma^2}{255^2} 计算得到的。由此可知上述代码添加的是 (\mu=0, \sigma^2_t=0.01384) 的高斯分布噪音。 4. 网络结构先定义一下计算PSNR的函数: #PSNR的计算公式这里不再赘述 def calculate_psnr(img1, img2): return 10. * torch.log10(1. / torch.mean((img1 - img2) ** 2))随后定义残差块: class ResBlock(nn.Module): def __init__(self, inC, outC): super(ResBlock, self).__init__() self.layer1 = nn.Sequential(nn.Conv2d(inC, outC, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(outC), nn.PReLU()) self.layer2 = nn.Sequential(nn.Conv2d(outC, outC, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(outC)) def forward(self, x): resudial = x out = self.layer1(x) out = self.layer2(out) out = out + resudial return out如上代码,一个残差块的结构为两个卷积核大小为 3\times3 ,卷积步长为1,填充为1的二维卷积层,第一个卷积层后接一个批量归一化层,随后应用PReLU激活函数;第二个卷积层不应用激活函数。卷积层的通道数为outC,这个参数将在后面确定。如上设置能确保输入图片与输出图片的大小不会改变,仅改变通道数。 接下来定义生成器: class Generator(nn.Module): def __init__(self, n_blocks): super(Generator, self).__init__() self.convlayer1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=9, stride=1, padding=4, bias=False), nn.PReLU()) self.ResBlocks = nn.ModuleList([ResBlock(64, 64) for _ in range(n_blocks)]) #叠加n_blocks个残差块 self.convlayer2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(64)) self.convout = nn.Conv2d(64, 3, kernel_size=9, stride=1, padding=4, bias=False) def forward(self, x): out = self.convlayer1(x) residual = out for block in self.ResBlocks: out = block(out) out = self.convlayer2(out) out = out + residual out = self.convout(out) return out生成器的结构如上,看代码应该能很清晰地看出来,就不再赘述了,主要是我懒。工作流程为图片输入生成器,通过convlayer1后的结果保存为残差out,out通过每个残差块前都会保存一个小残差x,并在每个残差块后面和残差块的输出相加,而最初的残差out会和convlayer2的输出相加然后通过convout得到生成器的最终输出。我语言组织能力不行,看图更直观,蓝色箭头就是残差相加,上述残差相加都是元素范围上的相加。还整不明白就去看看其他人写的ResNet的资料。 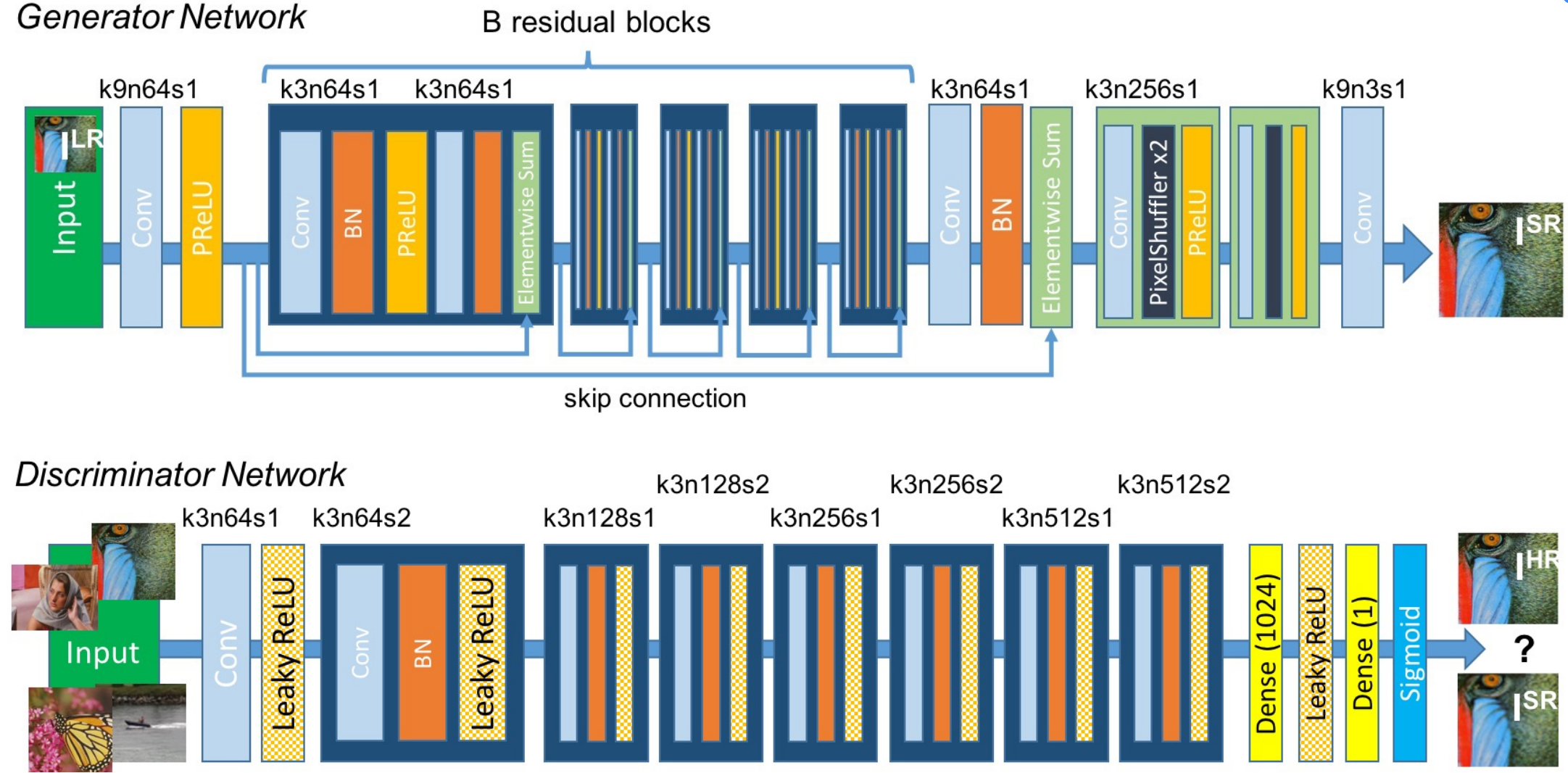 图1:注意判别器是没有残差的 图1:注意判别器是没有残差的接下来定义一下判别器: #下采样 class DownSample(nn.Module): def __init__(self, input_channel, output_channel, stride, kernel_size=3, padding=1): super(DownSample, self).__init__() self.layer = nn.Sequential(nn.Conv2d(input_channel, output_channel, kernel_size, stride, padding), nn.BatchNorm2d(output_channel), nn.LeakyReLU(inplace=True)) def forward(self, x): x = self.layer(x) return x #判别器 class Discriminator(nn.Module): def __init__(self): super(Discriminator, self).__init__() self.conv1 = nn.Sequential(nn.Conv2d(3, 64, 3, stride=1, padding=1), nn.LeakyReLU(inplace=True)) self.down = nn.Sequential(DownSample(64, 64, stride=2, padding=1), DownSample(64, 128, stride=1, padding=1), DownSample(128, 128, stride=2, padding=1), DownSample(128, 256, stride=1, padding=1), DownSample(256, 256, stride=2, padding=1), DownSample(256, 512, stride=1, padding=1), DownSample(512, 512, stride=2, padding=1)) self.dense = nn.Sequential(nn.AdaptiveAvgPool2d(1), nn.Conv2d(512, 1024, 1), nn.LeakyReLU(inplace=True), nn.Conv2d(1024, 1, 1), nn.Sigmoid()) #Loss为nn.BCELoss则加Sigmoid,若为nn.BCEWithLogitsLoss则不加,因为此Loss里包括了Sigmoid def forward(self, x): x = self.conv1(x) x = self.down(x) x = self.dense(x) return x结构如图1的Discriminator部分,所有下采样层的卷积核大小都3,其他如步长和填充等如上所示,与SRGAN原版一样。如上图1中,卷积核大小为k,通道数为n;则“k3n64s1”则为卷积核大小3,通道数64,步长1。 定义训练参数和实例化网络: lr = 0.001 G = Generator(n_blocks) D = Discriminator() G_loss = PerceptualLoss(device) #自定义的loss函数 Regulaztion = RegularizationLoss().to(device) #自定义的loss函数 D_loss = nn.BCELoss().to(device) optimizer_g = torch.optim.Adam(G.parameters(), lr=lr*0.1) #先训练判别器,后训练生成器,因此生成器的学习率比判别器小 optimizer_d = torch.optim.Adam(D.parameters(), lr=lr) real_label = torch.ones([batch_size, 1, 1, 1]).to(device) fake_label = torch.zeros([batch_size, 1, 1, 1]).to(device) early_stopping = EarlyStopping(10, verbose=True) #数据记录用 train_loss_g = [] train_loss_d = [] train_psnr = [] val_loss = [] val_psnr = []5. loss.py在写训练函数前先介绍一下自定义的loss函数,保存在loss.py内: #loss.py import torch import torch.nn as nn import torchvision.models as models #SRGAN使用预训练好的VGG19,用生成器的结果以及原始图像通过VGG后分别得到的特征图计算MSE,具体解释推荐看SRGAN的相关资料 class VGG(nn.Module): def __init__(self, device): super(VGG, self).__init__() vgg = models.vgg19(True) for pa in vgg.parameters(): pa.requires_grad = False self.vgg = vgg.features[:16] self.vgg = self.vgg.to(device) def forward(self, x): out = self.vgg(x) return out #内容损失 class ContentLoss(nn.Module): def __init__(self, device): super().__init__() self.mse = nn.MSELoss() self.vgg19 = VGG(device) def forward(self, fake, real): feature_fake = self.vgg19(fake) feature_real = self.vgg19(real) loss = self.mse(feature_fake, feature_real) return loss #对抗损失 class AdversarialLoss(nn.Module): def __init__(self): super().__init__() def forward(self, x): loss = torch.sum(-torch.log(x)) return loss #感知损失 class PerceptualLoss(nn.Module): def __init__(self, device): super().__init__() self.vgg_loss = ContentLoss(device) self.adversarial = AdversarialLoss() def forward(self, fake, real, x): vgg_loss = self.vgg_loss(fake, real) adversarial_loss = self.adversarial(x) return vgg_loss + 1e-3*adversarial_loss #正则项,需要说明的是,在SRGAN的后续版本的论文中,这个正则项被删除了 class RegularizationLoss(nn.Module): def __init__(self): super().__init__() def forward(self, x): a = torch.square( x[:, :, :x.shape[2]-1, :x.shape[3]-1] - x[:, :, 1:x.shape[2], :x.shape[3]-1] ) b = torch.square( x[:, :, :x.shape[2]-1, :x.shape[3]-1] - x[:, :, :x.shape[2]-1, 1:x.shape[3]] ) loss = torch.sum(torch.pow(a+b, 1.25)) return loss6. 训练函数def train(generator, discriminator, train_iter, val_iter, n_epochs, optimizer_g, optimizer_d, loss_g, loss_d, Regulaztion, device): print('train on',device) generator.to(device) discriminator.to(device) cuda = next(generator.parameters()).device for epoch in range(n_epochs): train_epoch_loss_g = [] #数据记录用 train_epoch_loss_d = [] train_epoch_psnr = [] val_epoch_loss = [] val_epoch_psnr = [] start = time.time() #开始时间 generator.train() #设置为训练模式 discriminator.train() for i, (img, nimg) in enumerate(train_iter): img, nimg = img.to(cuda).float(), nimg.to(cuda).float() fakeimg = generator(nimg) #生成器生成“假”图片,即降噪后的图片 optimizer_d.zero_grad() realOut = discriminator(img) #判别器对“真”图片,即原始图片的判断,1为真,0为假 fakeOut = discriminator(fakeimg.detach()) #判别器对“假”图片,即生成器生成的图片的判断,1为真,0为假 loss_d = D_loss(realOut, real_label) + D_loss(fakeOut, fake_label) #判别器的损失 loss_d.backward() optimizer_d.step() optimizer_g.zero_grad() loss_g = G_loss(fakeimg, img, D(fakeimg)) + 2e-8*Regulaztion(fakeimg) #生成器的损失,这里加了正则项 loss_g.backward() optimizer_g.step() train_epoch_loss_d.append(loss_d.item()) #记录判别器损失 train_epoch_loss_g.append(loss_g.item()) #记录生成器损失 train_epoch_psnr.append(calculate_psnr(fakeimg, img).item()) #记录PSNR train_epoch_avg_loss_g = np.mean(train_epoch_loss_g) #计算一个epoch的平均损失 train_epoch_avg_loss_d = np.mean(train_epoch_loss_d) train_epoch_avg_psnr = np.mean(train_epoch_psnr) #计算一个epoch的平均PSNR train_loss_g.append(train_epoch_avg_loss_g) #记录生成器的一个epoch的平均损失 train_loss_d.append(train_epoch_avg_loss_d) #记录判别器的一个epoch的平均损失 train_psnr.append(train_epoch_avg_psnr) #记录一个epoch的平均PSNR print(f'Epoch {epoch + 1}, Generator Train Loss: {train_epoch_avg_loss_g:.4f}, ' f'Discriminator Train Loss: {train_epoch_avg_loss_d:.4f}, PSNR: {train_epoch_avg_psnr:.4f}') #打印epoch训练结果 generator.eval() #设置为验证模式 discriminator.eval() with torch.no_grad(): #不需要计算梯度 for i, (img, nimg) in enumerate(val_iter): #验证就是简化版的训练,对照着看下,不赘述了 img, nimg = img.to(cuda).float(), nimg.to(cuda).float() fakeimg = generator(nimg) loss_g = G_loss(fakeimg, img, D(fakeimg)) + 2e-8*Regulaztion(fakeimg) val_epoch_loss.append(loss_g.item()) val_epoch_psnr.append(calculate_psnr(fakeimg, img).item()) val_epoch_avg_loss = np.mean(val_epoch_loss) val_epoch_avg_psnr = np.mean(val_epoch_psnr) val_loss.append(val_epoch_avg_loss) val_psnr.append(val_epoch_avg_psnr) print(f'Generator Val Loss: {val_epoch_avg_loss:.4f}, PSNR: {val_epoch_avg_psnr:.4f}, Cost: {(time.time()-start):.4f}s') checkpoint_perf = early_stopping(generator, discriminator, train_epoch_avg_psnr, val_epoch_avg_psnr) #应用早停法,选出PSNR最高的那个 if early_stopping.early_stop: print("Early stopping") print('Final model performance:') print(f'Train PSNR: {checkpoint_perf[0]}, Val PSNR: {checkpoint_perf[1]}') break torch.cuda.empty_cache() #清空显存缓存,可以不加这个训练函数包括了训练和验证,因此写的比较长,具体解释看注释。early-stopping的代码如下: #earlystopping.py import torch class EarlyStopping: def __init__(self, patience=7, verbose=False, delta=0): self.patience = patience #等待多少个epoch之后停止 self.verbose = verbose #是否显示日志 self.counter = 0 #计步器 self.best_score = None #记录最好性能 self.early_stop = False #早停触发 self.val_psnr_min = 0 #记录最小的验证PSNR self.delta = delta #可以给最好性能加上的小偏置 self.checkpoint_perf = [] #记录检查点的性能 def __call__(self, g, d, train_psnr, val_psnr): score = val_psnr self.early_stop = False if self.best_score is None: self.best_score = score self.save_checkpoint(g, d, val_psnr) elif score < self.best_score + self.delta: #PSNR越大越好,因此这里是小于,若使用loss做指标,这里应改成大于 self.counter += 1 #若当前性能不超过前一个epoch的性能则计步器+1 print(f'EarlyStopping counter: {self.counter} out of {self.patience}') if self.counter >= self.patience: #计步器累计到达极限,出发早停 self.early_stop = True self.counter = 0 self.best_score = None self.val_psnr_min = 0 else: #当前性能优于或等于前一个epoch的性能,则更新最佳性能记录 self.best_score = score self.save_checkpoint(g, d, val_psnr) #保存检查点 self.counter = 0 #计步器重置 self.checkpoint_perf = [train_psnr, val_psnr] #记录检查点性能数据 return self.checkpoint_perf def save_checkpoint(self, g, d, val_psnr): #保存检查点 self.val_psnr_min = val_psnr if self.verbose: print(f'Validation PSNR increased ({self.val_psnr_min:.6f} --> {val_psnr:.6f}). Saving model ...') torch.save(g.state_dict(), 'Generator.pth') torch.save(d.state_dict(), 'Discriminator.pth') else: torch.save(g.state_dict(), 'Generator.pth') torch.save(d.state_dict(), 'Discriminator.pth')准备好后,使用如下代码开始训练: train(G, D, train_iter, val_iter, n_epochs, optimizer_g, optimizer_d, G_loss, D_loss, Regulaztion, device)7. 测试与演示#读取模型参数 model = Generator(n_blocks) model.load_state_dict(torch.load('Generator.pth', map_location=torch.device('cpu'))) model.eval()这里我们只用一张图片用于演示,即原文中的蝴蝶图,文件名为img_011_SRF_4_HR.png。 test_transform = transforms.ToTensor() testimg = Image.open('img_011_SRF_4_HR.png') timg = np.array(testimg)/255 timg = addGaussNoise(timg, 30) timg = torch.tensor(timg.transpose(2,0,1)).float().unsqueeze(0)将图片读入后添加高斯噪声,随后使用生成器降噪。 dnimg = model(timg)[0, :, :, :] dnimg = dnimg.detach().numpy().transpose((1, 2, 0))随后将噪声图像和降噪后的图像恢复并保存: #噪声图像 timg = Image.fromarray(np.uint8(cv2.normalize(timg.squeeze().detach().numpy().transpose(1,2,0), None, 0, 255, cv2.NORM_MINMAX))) timg.save('noiseimg_011_SRF_4_HR.png') #降噪后的图像 img = Image.fromarray(np.uint8(cv2.normalize(dnimg, None, 0, 255, cv2.NORM_MINMAX))) img.save('set5_gan_test.png') 图2:原始图片(左),噪声图片(中),降噪图片(右)8. 批量降噪并保存#设置图片输出位置
outPath = './output_file/'
#图像重建函数
def reconstruct(model, test_iter, outPath, device):
print("Reconstructing")
model.to(device)
for i, (img, nimg) in enumerate(test_iter):
nimg = nimg.to(device).float()
dnimg = model(nimg)
img = img.detach().cpu().numpy().transpose(0,2,3,1)
dnimg = dnimg.detach().cpu().numpy().transpose(0,2,3,1)
nimg = nimg.detach().cpu().numpy().transpose(0,2,3,1)
for t in range(img.shape[0]):
rawimgs = Image.fromarray(np.uint8(cv2.normalize(img[t,:,:,:], None, 0, 255, cv2.NORM_MINMAX))) #原始图像
nimgs = Image.fromarray(np.uint8(cv2.normalize(nimg[t,:,:,:], None, 0, 255, cv2.NORM_MINMAX))) #噪声图像
dnimgs = Image.fromarray(np.uint8(cv2.normalize(dnimg[t,:,:,:], None, 0, 255, cv2.NORM_MINMAX))) #降噪图像
dnimgs.save(outPath + f'{i*batch_size+t}_DN.png')
nimgs.save(outPath + f'{i*batch_size+t}_N.png')
rawimgs.save(outPath + f'{i*batch_size+t}.png')
print("Finished, images are saved at", outPath) 图2:原始图片(左),噪声图片(中),降噪图片(右)8. 批量降噪并保存#设置图片输出位置
outPath = './output_file/'
#图像重建函数
def reconstruct(model, test_iter, outPath, device):
print("Reconstructing")
model.to(device)
for i, (img, nimg) in enumerate(test_iter):
nimg = nimg.to(device).float()
dnimg = model(nimg)
img = img.detach().cpu().numpy().transpose(0,2,3,1)
dnimg = dnimg.detach().cpu().numpy().transpose(0,2,3,1)
nimg = nimg.detach().cpu().numpy().transpose(0,2,3,1)
for t in range(img.shape[0]):
rawimgs = Image.fromarray(np.uint8(cv2.normalize(img[t,:,:,:], None, 0, 255, cv2.NORM_MINMAX))) #原始图像
nimgs = Image.fromarray(np.uint8(cv2.normalize(nimg[t,:,:,:], None, 0, 255, cv2.NORM_MINMAX))) #噪声图像
dnimgs = Image.fromarray(np.uint8(cv2.normalize(dnimg[t,:,:,:], None, 0, 255, cv2.NORM_MINMAX))) #降噪图像
dnimgs.save(outPath + f'{i*batch_size+t}_DN.png')
nimgs.save(outPath + f'{i*batch_size+t}_N.png')
rawimgs.save(outPath + f'{i*batch_size+t}.png')
print("Finished, images are saved at", outPath)这个函数会把原始图像、噪声图像,以及降噪后的图像都保存下来,不要随意使用,注意磁盘用量。 完 |
【本文地址】